Hash
Creating hash files
To create a hash file you must first select the directory in the File Tree for which you wish to create a hash file.
Hash file can be only created for directory with all subdirectories.
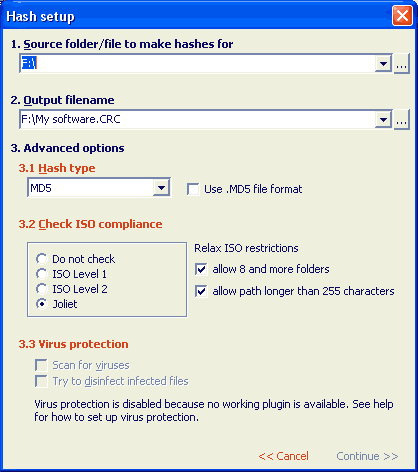
After that press "Hash" button to show the Hash setup confimation (image above). Here you can correct the selected directory and
specify alternative hash filename (and directory) for output. If hash file already exists with this name it will be overwritten!!
Press Continue to start creating hash file or press Cancel to exit Hash file setup.
CDCheck by default suggests the name of output hash file. This name is generated as following:
- source is fixed drive DRV (hard drive etc.) => DRV\drive_DRV.CRC
- source is non-fixed drive DRV with volume VOL (cdrom etc.) => DRV\volume_VOL.CRC
- source is non-root directory DIR => DIR\DIR.CRC
- source is a file FILE => FILE.CRC
(for MD5 file format and SFV file format file extension is changed to .md5 and .sfv)
You can create multiple hash files in a single directory and subdirectories. When checking using automatic detection all the
hash files are detected. The hash value of the file being checked is compared against the latest calculated hash value.
If multiple hash files contain a hash for file being checked then the one with the latest date written in the hash file is
used (if date is not written, file's "Modified time"="last write time" is used).
This is for example useful when burning multiple session CDs and importing previous session.
In this case when burning next session (and hash is already present for sessions before) you need to add only a hash file
(with unique name) for the last session.
Note! Hash file is always created relative to the selected source directory. For automatic detection to work during
checking, hash file should be put in the source directory after creation or should be already created there. However if it cannot be
in the source directory (if directory is read only or you do not have enough privileges) you can specify alternative output
filename (in different directory) and later use custom hash option in Checking to use it.
Note! If you manually stop hash file creation the hash file with values calculated till then will be deleted.
Tip 1: if you do not need the setup confirmation dialog you can hold shift down while clicking the button and
the hash will start with last options used and selected directory as source directory.
Tip 2: the output hash filename directory can be set to "default hash directory" set in "Options" by setting focus to
output hash filename and selecting the first item (pressing key down)
Warning (advanced users): under Win95,98,Me it is not recommended to create hash files on directories containing directory/filenames with non-locale characters
(for example Chinese characters on US version of Win98). These "non-locale files" can be produced only by some other OS and are easy recognizable
since they contain '_' character and they cannot be copied by Windows Explorer.
Other Hash setup options
- Hash type: here you can select what kind of hash code to calculate for files
- Use .MD5 file format: uses the same format as GNU utility MD5sum and some other utilites for calculating MD5 hash files.
- Use .SFV file format: uses the same format as WinSFV utility and some other utilites for calculating CRC-32 hash files.
- Check ISO Compliance: here you can set restrictions on filename and path length for compliance with different ISO standards for burning on CDs.
Hash types and file formats
CDCheck supports the following hashes:
MD2, MD4, MD5, CRC-32, Adler32, Gost, Haval (128,160,192, 224, 256), SHA (1, 256, 384, 512), Tiger (128, 160, 192), RipeMD (128, 160).
Most used hashes are CRC-32, MD5 and SHA. Because of popularity first two hash types (MD5 and CRC32) also
have its own established file formats. CRC-32 has a file format with extension .SFV. It was designed for use in WinSFV software and
was adopted by many CRC checkers. MD5 format originates from Linux. It is output of GNU md5sum utility and very established in
Linux community.
If you are wondering what are the numbers that are beside the word, they are related to the length of the hash calculated. Usually
the longer the hash is the more it is reliable. For more information on hash algorithms or specific hash algorithm I recommend you search the internet.
I recommend you use MD5 algorithm. It is more reliable than CRC-32, however it does takes more processor power to calculate, so it can be slower.
What exactly is hash and hash file?
Hash is some sort of a fingerprint of some information (data). It is designed
to produce a code of specific length (somewhere between 8 and 512 bits) that satisfies the following:
- Every bit in the message contributes to the hash. This means that changing any bit in the message should change the hash.
- Relatively small changes in the message should always result in changes in the hash. We want to be sure that it would
take an extremely unlikely combination of errors to produce an identical hash.
- The histogram of output hash values for input messages should tend to be flat. For a given input message, we want
the probability of a given hash being produced to be nearly equal across the entire range of possible hash values (for example 0h to FFh for 8 bit hashes).
CRC stands for Cyclic redundancy code. It is a code that provides efficient error detection. It is used by
many programs (for example Zip compression programs, communication protocols...). There are many variants of this code.
In CDCheck CRC-32 algorithm is used to produce CRC-32 code.
CRC is also often used for reference to general hash code.
CRC-32 is an acronym for the 32 bit Cyclical Redundancy Check algorithm. CRC-32 generally refers to a specific
32 bit CRC formula sanctioned by the CCITT, an international standards body primarily concerned with telecommunications.
CRC-32 is used in communications protocols such as HDLC and ZMODEM to verify the integrity of blocks of data being
transferred through various media.
MD5 stands for Message Digest 5 algorithm. Algorithm developed by Professor Ronald L. Rivest of MIT and used in many applications.
hash file is a file that contains hash codes for files or other data (CDCheck CRC file, .SFV file, .MD5 file).
What are the differences between different hash files?
CDCheck CRC file is a file that contains hash code (MD5, CRC-32...) separately for each file
in source directory and its subdirectories. It is written in Unicode format and optimized for low file size.
It is better than SFV or MD5 format however it is currently not implemented in any other software.
SFV file is a file that contains hash code of type CRC-32 only. It is written in Ansi format and originally used by WinSFV.
Many other programs are using it.
MD5 file is a file that contains hash code of type MD5 only. It is written in Ansi format and is used by GNU utility MD5sum.
It is therefore natively supported on Linux but also a lot of other software uses it.
How reliable is CRC-32 code?
CRC-32 code is 32 bit number (code) generated by CRC-32 algorithm based on data input (in our case file content).
This code is some sort of a "fingerprint". However it differs somewhat from the human fingerprint.
It is often said that no two people have identical fingerprints. This can't be the case for our CRC fingerprint.
Since there are more than 4,294,967,296 different files in the world, it is a foregone conclusion that some
of them must have identical codes. However, the CRC-32 does satisfy all the above mentioned requirements for hash code.
They were the goals that the CCITT had in mind when selecting the CRC-32 algorithm. In practice, the chances of
inadvertently damaging or modifying a file without modifying the CRC is vanishingly small, so for all practical
purposes testing CRC code to detect changes can be considered to be infallible.
However if file would be intentionally damaged (for example by a virus) the CRC could be restored to its previous state.
This could be done by using using brute force method to add some bytes to end of the file. So this is one thing it cannot protect
you from (although this is almost never done).
MD5 hash
MD5 was developed by Professor Ronald L. Rivest of MIT. What it does, to quote the executive summary of rfc1321, is:
The MD5 algorithm takes as input a message of arbitrary length and produces as output a 128-bit "fingerprint" or "message
digest" of the input. It is conjectured that it is computationally infeasible to produce two messages having the same message digest,
or to produce any message having a given prespecified target message digest. The MD5 algorithm is intended for digital signature applications,
where a large file must be "compressed" in a secure manner before being encrypted with a private (secret) key under a public-key cryptosystem such as RSA.
In essence, MD5 is a way to verify data integrity, and is much more reliable than checksum and many other commonly used methods.
ADVANCED: CDCheck's CRC file format
CRC file is written in Unicode text format. To indicate that file is Unicode at the beginning the character FEFFh is written.
Further the file consists of two sections. These are header and data.
Header
In header basic information is written about file format version, hash type and date of file creation. Currently
only Date and Format are changing while the rest of the header is fixed. Date must be of form dd.mm.yyyy.
[Info]
Version=1
Format=[Fmt]
Date=19.07.2001
[Fmt] can be CRC-32, MD5, MD2, SHA512, RIPEMD128...
Data
In [Data] section the hash codes of files are written. Lines following [Data] are of DIR or FILE type.
The order of files and directories is determined by the following sort algorithm:
- files in directory are tested first then directories
- files and directories are sorted by name using LANG_ENGLISH and SUBLANG_NEUTRAL.
DIR type: DIR [directory]
[directory] is full relative path of directory where the files following this line are in.
FILE type: [Hash] [file name]
[Hash] is calculated hash code (depending on Format specified in Info section) of file [file name]
Example:
[Info]
Version=1
Format=CRC-32
Date=19.07.2001
[Data]
DIR Start Menu\Programs\
B1E71BFF CDCheck.lnk
9DF41063 CDMASTER.lnk
DIR Start Menu\Programs\Utils\
4D6985CE Gibby.exe
ADVANCED: hash implementation
Hash is implemented using concurrent reading and hash calculation. This is done by
writing data from media into intermediate buffer in one thread and reading from buffer and
calculating hash values in other thread. Hash values are written to disk as they are calculated
to minimize memory usage.
Copyright (C) 2003-2008, Mitja Perko (CDCheck homepage)